PostgreSQL Table Partitioning
This tutorial explains how to use PostgreSQL Table Partitioning with Bun.
Why partition a table?
Table partitioning allows to split one large table into smaller ones bringing the following benefits:
- Smaller tables are faster both for reading and writing.
- You can very efficiently drop the whole partition instead of deleting data row by row.
- Because PostgreSQL knows how to prune unused partitions, you can use partitions as a crude index. For example, by paritioning a table by date, you may not need an index on the date field any more and use a sequential scan instead.
- Rarely used partitions can be moved to a cheaper storage.
Partitioning methods
Let's suppose we have a table:
CREATE TABLE measurements (
id int8 NOT NULL,
value float8 NOT NULL,
date timestamptz NOT NULL
);
You can partition that table by providing columns to use as the partition key:
CREATE TABLE measurements (
id int8 NOT NULL,
value float8 NOT NULL,
date timestamptz NOT NULL
) PARTITION BY RANGE (date);
PostgreSQL supports several partitioning methods which only differ in the way they specify row values for the partition key.
Partition by range
Partitioning by range allows to specify a range of values for the partition, for example, we can store data for each month in a separate partition:
CREATE TABLE measurements_y2021m01 PARTITION OF measurements
FOR VALUES FROM ('2021-01-01') TO ('2021-02-01');
Partition by list
List partitioning allows to specify a list of values for the partition, for example, we can store small fraction of the frequently accessed data in the hot partition and move the rest to the cold partition:
CREATE TABLE measurements (
id int8 PRIMARY KEY,
value float8 NOT NULL,
date timestamptz NOT NULL,
hot boolean
) PARTITION BY LIST (hot);
CREATE TABLE measurements_hot PARTITION OF measurements
FOR VALUES IN (TRUE);
CREATE TABLE measurements_cold PARTITION OF measurements
FOR VALUES IN (NULL);
You can then move rows between partitions by updating the hot column:
-- Move rows to measurements_hot
UPDATE measurements SET hot = TRUE;
-- Move rows to measurements_cold
UPDATE measurements SET hot = NULL;
Partition by hash
Partitioning by hash allows to uniformly distribute rows into a set of tables, for example, we can create 3 partitions for our table and pick a partition for the row using a hash and a remainder of division:
CREATE TABLE measurements (
id int8 PRIMARY KEY,
value float8 NOT NULL,
date timestamptz NOT NULL
) PARTITION BY HASH (id);
CREATE TABLE measurements_1 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE measurements_2 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE measurements_3 PARTITION OF measurements
FOR VALUES WITH (MODULUS 3, REMAINDER 2);
Thanks to using hashes, the partitions will receive approximately the same amount of rows.
Managing partitions
PostgreSQL allows to detach and attach partitions:
ALTER TABLE measurements DETACH PARTITION measurements_y2021m01;
ALTER TABLE measurements ATTACH PARTITION measurements_y2021m01
FOR VALUES FROM ('2021-01-01') TO ('2021-02-01');
You can use those commands to partition an existing table without moving any data:
-- Use the existing table as a partition for the existing data.
ALTER TABLE measurements RENAME TO measurements_y2021m01;
-- Create the partitioned table.
CREATE TABLE measurements (LIKE measurements_y2021m01 INCLUDING DEFAULTS INCLUDING CONSTRAINTS)
PARTITION BY RANGE (date);
-- Attach the existing partition with open left constraint.
ALTER TABLE measurements ATTACH PARTITION measurements_y2021m01
FOR VALUES FROM ('0001-01-01') TO ('2021-02-01');
-- Use proper constraints for new partitions.
CREATE TABLE measurements_y2021m02 PARTITION OF measurements
FOR VALUES FROM ('2021-02-01') TO ('2021-03-01');
Using partitioned tables with Bun
Bun allows to create partitioned tables:
type Measure struct {
ID int64
Value float64
Date time.Time
Hot bool `bun:",nullzero"`
}
_, err := db.NewCreateTable().
Model((*Measure)(nil)).
PartitionBy("LIST (hot)").
Exec(ctx)
And query partitions directly using ModelTableExpr:
var measures []*Measure
num, err := db.NewSelect(&measures).
ModelTableExpr("measurements_hot").
Count(ctx)
You can even create separate models for partitions:
type MeasureHot struct {
bun.BaseModel `bun:"measures_hot"`
Measure
}
type MeasureCold struct {
bun.BaseModel `bun:"measures_cold"`
Measure
}
PostgreSQL monitoring
To monitor PostgreSQL, you can use OpenTelemetry PostgreSQL receiver that comes with OpenTelemetry Collector.
OpenTelemetry Collector is commonly used for monitoring and observability purposes in modern software applications and distributed systems. It plays a crucial role in gathering telemetry data from various sources, processing that data, and exporting it to monitoring and observability backends for analysis and visualization.
Uptrace is a Grafana alternative that supports distributed tracing, metrics, and logs. You can use it to monitor applications and troubleshoot issues.
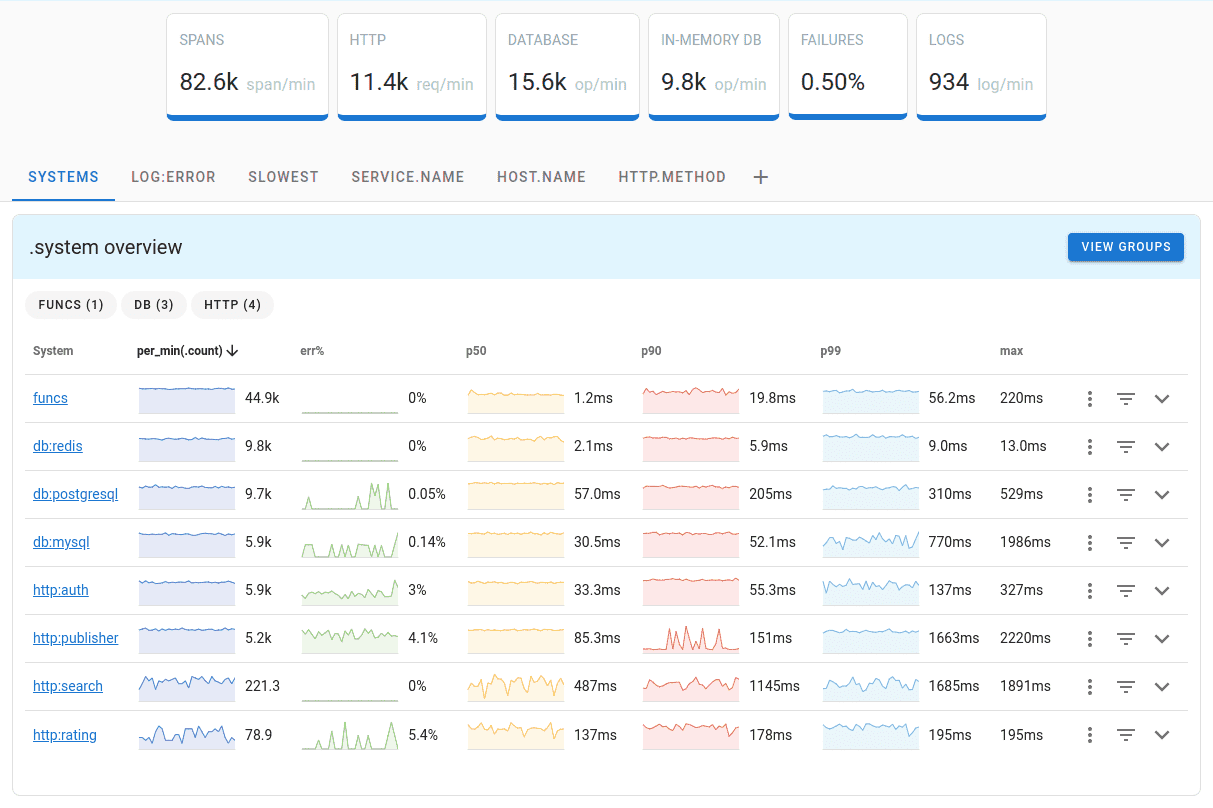
Uptrace comes with an intuitive query builder, rich dashboards, alerting rules with notifications, and integrations for most languages and frameworks.
Uptrace can process billions of spans and metrics on a single server and allows you to monitor your applications at 10x lower cost.
In just a few minutes, you can try Uptrace by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.