Zero-downtime PostgreSQL migrations
Zero-downtime PostgreSQL migrations are essential for maintaining the availability and reliability of your application while making changes to the database schema or performing other maintenance tasks.
Follow these simple rules to avoid common pitfalls and apply changes to your database without unplanned downtime.
Use transactions
Enclose your migration scripts in a transaction block. If any part of the migration fails, the entire transaction will be rolled back, ensuring that your database remains in its previous state.
Avoid long-running transactions
Running a migration in a transaction means that changes made within a transaction are not visible until the end of a transaction. That is exactly what we need when we apply a migration, but in practice it does not work well.
Using a transaction causes PostgreSQL to maintain two versions of a database for the duration of a transaction. One version with your changes and one without. PostgreSQL transactions are well-suited for such task but they have their limits too.
PostgreSQL also has to hold all the locks ackquired during a migration. For example, updating a row locks the row so your changes are not overwritten by another transaction. PostgreSQL releases the lock only in the end of a transaction. And if a concurrent transaction actually changes the same row migrations fails.
Using transactions only works well if your migration is small and fast (less than 5-10 seconds). Even for a medium database, using long transactions either makes a migration slower (in some cases 10x slower) or causes a migration to fail.
Split long-running queries into smaller batches
PostgreSQL runs every query in a transaction. So not using BEGIN and COMMIT does not imply that you are not using transactions. Meaning that you need to split long running queries into smaller ones and avoid large transactions for the reasons we discussed above.
For example, you need to update 1 million rows. Don't do it with a single UPDATE query. Instead split the job into 10 batches each containing 100k rows. And execute the same UPDATE query separately on each batch. Now you have 10 queries instead of 1, but you can be sure that migration will succeed.
Update rows in a consistent order
When possible, update rows in a consistent order. This helps avoiding deadlocks when 2 concurrent transactions try to update the same rows but in a different order.
For example, deadlock happens when transaction 1 locks row #1 and transaction 2 locks row #2. Now transaction 1 waits for a lock on row #2 and transaction 2 waits for a lock on row #1. They lock each other and PostgreSQL has to kill one of them.
Bad:
-- transaction 1
UPDATE test WHERE id IN (1, 2);
-- transaction 2
UPDATE test WHERE id IN (2, 1);
Good:
-- transaction 1
UPDATE test WHERE id IN (1, 2);
-- transaction 2
UPDATE test WHERE id IN (1, 2);
The same rule applies when you are using INSERT ON CONFLICT DO UPDATE. In such case, you may need to sort rows before inserting them.
Don't add columns with NOT NULL
Queries like ADD column NOT NULL fail on tables that already have some rows. Because existing rows do not have values for the newly added column, PostgreSQL refuses to add the column.
> ALTER TABLE test ADD COLUMN foo text NOT NULL;
ERROR: column "foo" of relation "test" contains null values
Your alternatives are:
- Add a default value, for example,
foo text NOT NULL DEFAULT ''. - Drop
NOT NULLalthogether and add some validation againstNULLelsewhere. - Split the query into multiple migrations:
-- migration 1
ALTER TABLE test ADD COLUMN foo text;
-- migration 2
UPDATE test SET foo = '';
-- migration 3
ALTER TABLE test ALTER COLUMN foo SET NOT NULL;
Create temporary tables
In some cases, you can create temporary tables with the new schema, copy data from the old table, and then swap the tables atomically. This minimizes the downtime during migration.
Rolling deployments
Implement rolling deployments for your application. This involves deploying new code and migrating the database incrementally, one instance or node at a time, while keeping the others running.
Monitoring PostgreSQL
To monitor PostgreSQL, you can use OpenTelemetry PostgreSQL receiver that comes with OpenTelemetry Collector.
OpenTelemetry Collector is an agent that pulls telemetry data from systems you want to monitor and sends it to an OpenTelemetry backend using the OpenTelemetry protocol (OTLP).
Uptrace is a DataDog competitor that supports distributed tracing, metrics, and logs. You can use it to monitor applications and troubleshoot issues.
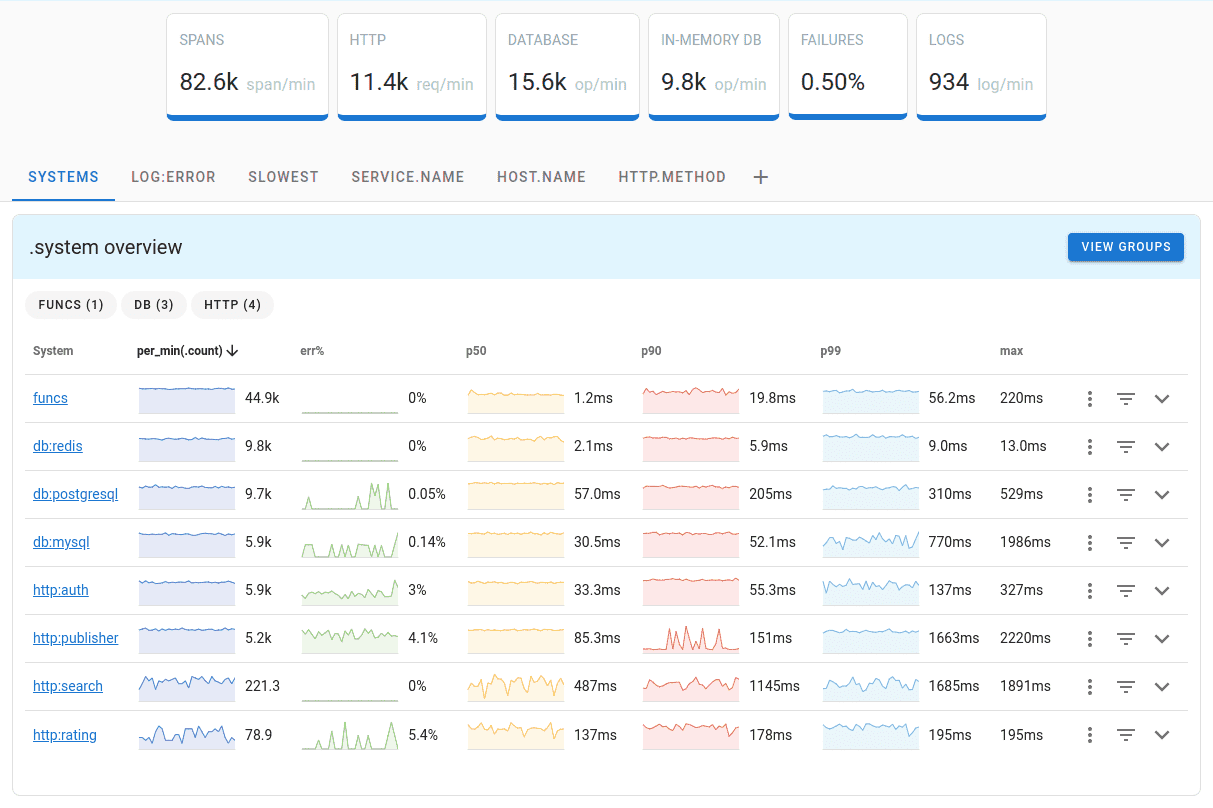
Uptrace comes with an intuitive query builder, rich dashboards, alerting rules with notifications, and integrations for most languages and frameworks.
Uptrace can process billions of spans and metrics on a single server and allows you to monitor your applications at 10x lower cost.
In just a few minutes, you can try Uptrace by visiting the cloud demo (no login required) or running it locally with Docker. The source code is available on GitHub.
Conclusion
Zero-downtime PostgreSQL migrations require careful planning, testing, and coordination. It's crucial to balance the need for making schema changes with the goal of maintaining a highly available and performant application.